|
-
September 22, 2025, 06:56:24 pm

- Welcome, Guest
News:Official site launch very soon, hurrah!
Show Posts
This section allows you to view all posts made by this member. Note that you can only see posts made in areas you currently have access to.
Messages - Dakusan
Pages: 1 2 [3] 4 5 ... 38
31
« on: January 19, 2020, 01:11:48 am »
I’ve always thought that the RSA and Diffie–Hellman public key encryption algorithm systems are beautiful in their complex simplicity. While there are countless articles out there explaining how to implement them, I have never really found one that I think describes the math behind then in a simple way, so I thought I’d give a crack at it. Both algorithms are derived from 3 math axioms: - This is called Modular exponentiation (hereby referred to as modexp). In the following, x is a prime numbers and p is an integer less than x.
p^(x ) mod x = p (e.x. 12^(17 ) mod 17 = 12) p^(x-1) mod x = 1 (e.x. 12^(17-1) mod 17 = 1 )
- A further derivation from the above formulas shows that we can combine primes and they work in the same manner. In the following, x and y are prime numbers and p is an integer less than x*y.
p^((x-1)*(y-1) ) mod (x*y) = 1 (e.x. 12^((13-1)*(17-1) ) mod (13*17) = 1 ) Note: This formula is not used in RSA but it helps demonstrate how the formulas from part 1 becomes formula 2b.
Due to how modexp works with primes, values of p that are multiples of x or y do not work with 2a. p^((x-1)*(y-1)+1) mod (x*y) = p (e.x. 12^((13-1)*(17-1)+1) mod (13*17) = 12)
- The final axiom is how modexp can be split apart the same way as in algebra where (x^a)^b === x^(a*b). For any integers p, x, y, and m:
(p^(x*y) mod m) === ((p^x mod m)^y mod m)
With these 3 axioms we have everything we need to explain how RSA works. To execute an RSA exchange, encrypted from Bob and decrypted by Alice, the following things are needed.
| The variable | Variable name | Who has it | Who uses it | Description |
|---|
| Prime Numbers 1 and 2 | Prime1, Prime2 | Alice | Alice | Alice will use these to derive variables PubKey, PrivKey, and Modulo. In our examples we use small numbers, but in reality, very large primes will be used, generally of at least 256 bit size. | | Public key | PubKey | Alice, Bob | Bob | Alice sends this to Bob so he can encrypt data to her. Bob uses it as an exponent in a modexp. | | Private key | PrivKey | Alice | Alice | Alice uses this to decrypt what Bob sends her. Alice uses it as an exponent in a modexp. | | Modulo | Modulo | Bob, Alice | Bob, Alice | Alice sends this to Bob. They both use it as a modulo in a modexp | | Payload Data | Payload | The data bob starts with and turns into EncryptedPayload. Alice derives Payload back from EncryptedPayload |
Now, let’s start with axiom 2b: Payload^((Prime1-1)*(Prime2-1)+1) mod (Prime1*Prime2) = Payload Let’s change this up so the exponent is just 2 multiplications so we can use axiom 3 on it. We need to find 2 integers to become PubKey and PrivKey such that: PubKey*PrivKey=(Prime1-1)*(Prime2-1)+1 And Modulo is Prime1*Prime2. So we now have: Payload^(PubKey*PrivKey) mod Modulo = Payload Now, using axiom 3, we can turn it into this: (Payload^PubKey mod Modulo)^PrivKey mod Modulo = Payload Now, we can split this up into:Bob calculates and sends to Alice: Payload^PubKey mod Modulo=EncryptedPayloadAlice uses the received EncryptedPayload and performs: EncryptedPayload^PrivKey mod Modulo = PayloadAnd the process is complete! However, there is 1 caveat that I didn’t cover which makes the encryption that what we currently have weak. The calculation of PubKey and PrivKey from Prime1 and Prime2 needs to follow some rather specific complex rules to make the keys strong. Without this, an attacker may be able to figure out Prime1 and Prime2 from the Modulo and PubKey, and could then easily derive PrivKey from it. I generally see the PubKey as 65535, or another power of 2 minus 1.
32
« on: January 10, 2020, 05:23:33 pm »
Tmux is a great alternative to gnu screen. I can’t believe I’ve never posted my custom Tmux config for Cygwin after all the work I put into it years ago. So here it is. Its features include: - Uses ctrl+a, like gnu screen, instead of ctrl+b
- Mouse interaction is enabled
- Tab bar/windows:
- Current tab is highlighted in cyan
- Cycle through tabbed windows with a click on its tab or ctrl+arrowkeys
- Reorder tabbed windows with a drag of its tab or alt+arrowkeys
- ctrl+a,/ to rename a tab on the tab bar
- Create new window with ctrl+a,c
- Panes
- Create split panes with vertical=ctrl+a,| and horizontal=ctrl+a,-
- Move around panes with click or ctrl+shift+arrowkeys
- Resize panes by dragging on the separator bar or use ctrl+shift+alt+arrowkeys
- Panes automatically resize to fit OS window
- Clipboard/highlighting
- Copy text to clipboard by highlighting it. Had to use a minor hack to fix a cygwin selection problem
- Paste from clipboard with right click
- Middle mouse button+drag starts copy mode
- When in copy mode, u runs the selection as a command in a separate window (Instead of “cygstart” for cygwin, use “xdg-open” for linux, or “open” for MacOS X)
- Double click selects word
- Double middle click runs the word under the mouse as a command
- Start the session on the current bash directory
- Escape time is lowered for quicker response to scroll buffer access (ctrl+a,pageup)
To use this, save the file to ~/.tmux.conf
#Set current directory setting for cygwin
set-environment -g CHERE_INVOKING 1
#Mouse interaction
set -g mouse on
#Lower escape timing from 500ms to 50ms for quicker response to scroll-buffer access
set -s escape-time 50
#Window always takes up largest possible max size
set-window-option -g aggressive-resize
#Highlight active window in tab-bar at bottom in cyan
set-window-option -g window-status-current-bg cyan
#Reorder windows in status bar by drag & drop
bind-key -n MouseDrag1Status swap-window -t=
#Copy to clipboard on text selection in cygwin. Move cursor position 1 to the right before copy to bypass a bug
bind -Tcopy-mode MouseDragEnd1Pane send-keys -X cursor-right\; send -X copy-selection-and-cancel\; run-shell -b "tmux show-buffer > /dev/clipboard"
#Paste from clipboard with right click in cygwin
bind-key -n MouseDown3Pane run-shell 'tmux set-buffer -b winclip "$(cat /dev/clipboard)"'\; paste-buffer -db winclip
#Middle drag starts copy mode
bind -n MouseDrag2Pane copy-mode -M
#When in copy mode, "u" runs the selection as a command in a separate window (Instead of "cygstart" for cygwin, use "xdg-open" for linux, or "open" for MacOS X)
bind -Tcopy-mode u send -X copy-selection-and-cancel\; run-shell -b "tmux show-buffer | xargs cygstart"
#Double click selects word
bind-key -n DoubleClick1Pane copy-mode -M\; send-keys -X select-word
#Double middle click runs the word under the mouse as a command. See description for MouseDown3Pane above
bind-key -n DoubleClick2Pane copy-mode -M\; send-keys -X select-word\; send -X copy-selection-and-cancel\; run-shell -b "tmux show-buffer | xargs cygstart"
#Remap prefix to Control+a
set -g prefix C-a
unbind C-b
#bind 'C-a C-a' to type 'C-a'
bind C-a send-prefix
#Start in CWD when creating or splitting tabs; move the splitting planes keys to | and -
bind '|' split-window -h -c '#{pane_current_path}' # Split panes horizontal
bind '-' split-window -v -c '#{pane_current_path}' # Split panes vertically
bind c new-window -c '#{pane_current_path}' # Create new window
unbind '"'
unbind %
#prefix, / -- Renames window, but starts blank
bind-key / command-prompt "rename-window '%%'"
#Select next/prev window with Ctrl+(Left|Right)
bind-key -n C-Right next-window
bind-key -n C-Left previous-window
#Reorder window with Alt+(Left|Right)
bind-key -n M-Left swap-window -t -1
bind-key -n M-Right swap-window -t +1
#Switch panes using Ctrl+Shift+arrow
bind -n C-S-Left select-pane -L
bind -n C-S-Right select-pane -R
bind -n C-S-Up select-pane -U
bind -n C-S-Down select-pane -D
#Resize panes using Ctrl+Shift+Alt+arrow
bind-key -n C-S-M-Up resize-pane -U 1
bind-key -n C-S-M-Down resize-pane -D 1
bind-key -n C-S-M-Left resize-pane -L 1
bind-key -n C-S-M-Right resize-pane -R 1
33
« on: September 24, 2019, 04:59:08 pm »
I recently decided to swap around my hard drives to different SATA slots so my most used hard drives were on the fastest ports. Unfortunately, when I did this, my computer stopped booting to Windows. I never did figure out why my bootable EFI partitions only showed up randomly in BIOS depending on which hard drives were plugged in, but I found a configuration the computer liked and I was able to see the Microsoft Boot EFI partition and EFI boots on my USB keys. The next step was to get the computer actually booting to something I could run commands on. When I try to boot directly to the EFI shell, the resolution is always screwed up and I can only see the top half of what should be visible, so I can’t actually see the command line I am typing too. This actually happens to everything I directly boot to that uses console text. The way around this for me is that I need to boot to the BIOS setup, and from there tell it to boot immediately to the EFI option of my choice when exiting the BIOS. From there, the proper resolution is used and everything is visible. Next, in the EFI shell, you can run map to see all of the available possible mounts. This should automatically run when the EFI shell starts anyways, so you should already have that information. Any detected EFI partition on any bootable device should be given a mapping of “fs#” where # is a number. In my case, it was fs0. So to mount that, I ran mount fs0 x. “x” could be whatever you want, it doesn’t really matter. It’s analogous to a drive letter in windows, and you can make it any string (within reason, I believe anything alphanumeric should be fine). So next you would run x: to switch to that drive. From there, you can run cd EFI\Microsoft\Boot and then bootmgfw.efi to boot to windows. Since I use VeraCrypt system encryption, I had to go to “EFI\VeraCrypt” and run DcsBoot.efi to finally boot into Windows through VeraCrypt. Finally, to get the Windows Boot manager to start with VeraCrypt, run in the Windows command prompt bcdedit /set '{bootmgr}' path \EFI\VeraCrypt\DcsBoot.efi.
34
« on: August 10, 2019, 10:48:07 pm »
I recently tried to install Slackware 4.2 64-bit (Linux) onto a new mini PC I just bought. The new PC only supports UEFI so I had major issues getting the darn setup on the install cd to actually run. I never DID actually get the install cd to boot properly on the system, so I used an alternative. While the slack install usb key was in, I also added and loaded up an ubuntu live cd usb key. The following is what I used to run the slackware setup in Ubuntu.
#Login as root
#sudo su
#Settings
InstallDVDName=SlackDVD #This is whatever you named your slackware usb key
#/mnt will contain the new file system for running the setup
cd /mnt
#Extract the initrd.img from the slackware dvd into /mnt
cat /media/ubuntu/$InstallDVDName/isolinux/initrd.img | gzip -d | cpio -i
#Bind special linux directories into the /mnt folder
for i in proc sys dev tmp; do mount -o bind /$i ./$i; done
#Mount the cdrom folder into /mnt/cdrom
rm cdrom
mount -o bind /media/ubuntu/$InstallDVDName/ ./cdrom
#Set /mnt as our actaul (ch)root
chroot .
#Run the slackware setup
usr/lib/setup/setup
#NOTE: When installing, your package source directory is at /cdrom/slackware64
35
« on: June 26, 2019, 09:53:33 pm »
It’s a bit of a pain reading results from batch requests to Mailchimp. Here is a quick and dirty bash script to get and pretty print the JSON output. It could be cleaned up a little, including combining some of the commands, but meh.
#Example variables
BATCHID=abc1234567;
APIKEY=abcdefg-us11@us11.api.mailchimp.com;
APIURL=us11.api.mailchimp.com;
#Request the batch information from Mailchimp
curl --request GET --url "https://dummy:$APIKEY@$APIURL/3.0/batches/$BATCHID" 2> /dev/null | \
#Get the URL to the response
grep -oP '"response_body_url":"https:.*?"' | \
grep -oP 'https:[^"]*' | \
#Get the response
xargs wget -O - 2> /dev/null | \
#The response is a .tar.gz file with a single file in it. So get the contents of this file
tar -xzvO 2> /dev/null | \
#Pretty print the json of the full return and the “response” objects within
php -r '$Response=json_decode(file_get_contents("php://stdin"), true); foreach($Response as &$R) $R["response"]=json_decode($R["response"], true); print json_encode($Response, JSON_PRETTY_PRINT);'
36
« on: April 08, 2019, 09:31:09 pm »
Part of my workstation’s audio setup uses the RME Babyface Pro. Until the most recent update of their software, the built-in Window’s sound’s master volume for the device was ignored. So while this script isn’t as important as before, I still find it very useful. So the following is an AutoHotkey script which modifies the master volume in the TotalMix FX window via the mousewheel (when alt+ctrl is held down). This expects the TotalMix FX window to be sized as small as it can, and to have a channel selected for the control room’s Main Out. It should look like this: 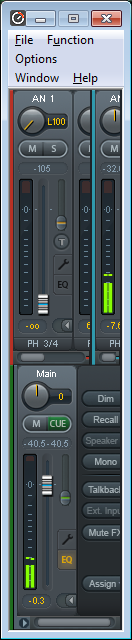 The script is as follows:
;Function to create lparam/wparam for SendMessage
CalculatePARAM(w1, w2)
{
IfLess, w1, 0
w1 := 65535 + w1 + 1
IfLess, w2, 0
w2 := 65535 + w2 + 1
return (w2<<16 | w1)
}
;Send a mouse wheel action to a window
SendMouseWheel(WindowHWND, Steps, XPos, YPos)
{
;Constants
WM_MOUSEWHEEL := 0x20A
WheelStepAmount := 120
;Calculate and execute the message
WinGetPos, ScreenX, ScreenY,,, ahk_id %WindowHWND%
wparam := CalculatePARAM(0, Steps*WheelStepAmount)
lparam := CalculatePARAM(XPos+ScreenX, YPos+ScreenY)
SendMessage, %WM_MOUSEWHEEL%, %wparam%, %lparam%,, ahk_id %WindowHWND%
}
^!WheelUp::
ControlGet, ControlHWND, Hwnd,,AfxFrameOrView100s1,RME TotalMix
if ControlHWND
SendMouseWheel(ControlHWND, 1, 36, 428)
return
^!WheelDown::
ControlGet, ControlHWND, Hwnd,,AfxFrameOrView100s1,RME TotalMix
if ControlHWND
SendMouseWheel(ControlHWND, -1, 36, 428)
return
37
« on: December 29, 2018, 04:48:03 am »
#This script takes a newline delimited file list from STDIN for md5 hashing
#This script requires the `md5sum`, `pv`, `paste`, `bc`, and 'numfmt' commands
#The output of the md5s are stored in the file specified by the first parameter
#The format for each md5 hash to the output file is "$FileName\t$Hash\n"
#File sizes are always output in megabytes with 3 decimal places
#While calculating the hashes the script keeps the user informed of the progress of both the current file and all the files as follows:
#1) Before file starts: "Hashing: $FileName ($FileSize MiB)\n"
#2) During transfer: The progress of the hash of the current file ran through `pv`
#3) During transfer: The progress of the hashing of all the files, ran through `pv`
#4) After transfer: "Finished $TotalProgressPercent% ($ProcessedBytes/$TotalBytes MiB)\n\n"
#Get $Outfile from the first argument and the $FileList from STDIN (newline delimited)
OutFile="$1";
FileList=`cat /dev/stdin`
#Format a byte count in MegaBytes with comma grouping and 3 decimal places
MbFmtNoExt ()
{
echo "scale=3; $1/1024/1024" | bc | echo -n `xargs numfmt --grouping`
}
#Add " MiB" to the end of MbFmtNoExt
MbFmt ()
{
echo `MbFmtNoExt $1`" MiB"
}
#Calculate and output the total size of the file list
echo -n "Calculating total size: "
TotalSize=`echo "$FileList" | xargs -d"\n" stat --printf="%s\n" | paste -s -d+ | bc`
MbFmt $TotalSize
echo #Add an extra newline
#Create a fifo to keep track of the total complete
TotalDoneFifo=$(mktemp)
TotalDoneBG=0
rm "$TotalDoneFifo"
mkfifo "$TotalDoneFifo"
cat > "$TotalDoneFifo" & #Do not close read of fifo
Cleanup() {
rm "$TotalDoneFifo"
kill $TotalDoneBG
exit 0
}
trap Cleanup SIGTERM SIGINT
#Start the TOTAL line
tail -f "$TotalDoneFifo" | pv -s $TotalSize -F "%b %t %p %e" > /dev/null &
TotalDoneBG=$!
#Run over the list (newline delimited)
CalculatedBytes=0
IFS=$'\n'
for FileName in `echo "$FileList"`
do
#Output the file size and name to STDOUT
FileSize=`stat --printf="%s" "$FileName"`
echo "Hashing: $FileName ("`MbFmt $FileSize`")"
#Output the filename to $OutFile
echo -n $FileName$'\t' >> $OutFile
#Run the md5 calculation with `pv` progress
#Output the hash to $OutFile after the FileName and a tab
cat "$FileName" | pv -s $FileSize -c | tee -a "$TotalDoneFifo" | md5sum | awk '{print $1}' >> $OutFile
#Output the current progress for the entire file list
#Format: "Finished $TotalProgressPercent% ($ProcessedBytes/$TotalBytes MiB)\n\n"
CalculatedBytes=$(($CalculatedBytes+$FileSize))
echo -n "Finished "
printf "%.3f" `echo "scale=4; $CalculatedBytes*100/$TotalSize" | bc`
echo "% ("`MbFmtNoExt $CalculatedBytes`"/"`MbFmt $TotalSize`$')\n'
done
Cleanup
38
« on: December 07, 2018, 03:29:27 pm »
On my primary computer (whose harddrive is encrypted) I always have Windows auto logging in to help with the bootup time. However, my bootup time can be rather slow; and if I needed to have my computer booted but locked, I had to wait for the login to complete so I could lock the computer. This has been becoming a nuisance lately when I need to get out of my house quickly in the morning. For the solution I created a windows boot entry that auto locks the computer after logging the user in. This also requires a batch file, to run for the user on startup, to detect when this boot entry was selected. Here are the steps to create this setup: - Create the new boot entry:In the windows command line, run: bcdedit /copy {current} /d "Lock on Startup"
This creates a new boot option, duplicated from your currently selected boot option, in the boot menu labeled “Lock on Startup”. - (Optional) Change the bootup timeout:In the windows command line, run: bcdedit /timeout 5
Where 5 is a 5 second timeout. - Create a batch file to run on login:In your start menu’s startup folder, add a batch file. You can name it anything as long as the extension is “.bat”.
Add the following to the file: bcdedit /enum {current} | findstr /r /c:"description *Lock on Startup" && rundll32.exe user32.dll,LockWorkStation
Note that there are 2 spaces in the description search string to replicate the regular expression's 1 or more quantifier “+”, since findstr only supports the 0 or more quantifier “*”.
39
« on: October 11, 2018, 09:27:26 pm »
It is not possible with the program, and would not be easy if the image size was different than the original.
However, if I recall (this project is almost 15 years old, so I could be remembering wrong) they are stored in 24bit uncompressed bitmap format in the container file, so if you search with a hex editor in the original file for a byte string from the extracted picture, you can find it, and replace it with another bitmap of the same size.
If it isn't stored in 24bit uncompressed format, the extracted images will probably still be the same as the original in the container file and you can still search for them in there with a hex editor. And as long as you replace it with a bitmap of equal or less size, it should work.
When replacing, make sure to replace the entire bitmap file in the container, including the bitmap header.
40
« on: August 30, 2018, 01:56:04 am »
I wanted a simple setup in Symfony where the programmer could define their ide in the parameters file. Sounds simple, right? Just add something like ide_url: 'phpstorm' to parameters.yml->parameters and ide: '%ide_url%' to config.yml->framework. And it worked great, however, my problem was much more convoluted. I am actually running the Symfony server on another machine and am accessing the files via NFS on Windows. So, it would try to open PHPStorm with the incorrect path. Symfony suggests the solution to this is writing your own custom URL handler with %f and %l to fill in the filename and line, and use some weird formatting to do string replaces. So I wrote in 'idea://%%f:%%l&/PROJECT_PATH_ON_SERVER/>DRIVE_LETTER:/PATH_ON_WINDOWS/' (note the double parenthesis for escaping) directly in the config.yml and that worked, kind of. The URL was perfect, but IntelliJ does not seem to register the idea:// protocol handler like PHPStorm theoretically does (according to some online threads) with phpstorm://. So I had to write my own solution. This answer on stackoverflow has the answer on how to register a protocol handler in Windows. But the problem now was that the first parameter passed to IntelliJ started with the idea:// which broke the command-line file-open. So I ended up writing a script to fix this, which is at the bottom. OK, so we’re almost there; I just had to paste the string I came up with back into the parameters.yml, right? I wish. While this was now working properly in a Symfony error page, a new problem arose. The Symfony bin/console debug:config framework command was failing with You have requested a non-existent parameter "f:". The darn thing was reading the unescaped string as 'idea://%f:%l&...' and it thought %f:% was supposed to be a variable. Sigh. So the final part was to double escape the strings with 4 percent signs. 'idea://%%%%f:%%%%l&...'. Except now the URL on the error pages gave me idea://%THE_PATH:%THE_LINE_NUMBER. It was adding an extra parenthesis before both values. This was simple to resolve in the script I wrote, so I was finally able to open scripts directly from the error page. Yay. So here is the final set of data that has to be added to make this work: Registry: HKCR/idea/(default) = URL:idea ProtocolHKCR/idea/URL Protocol = ""HKCR/idea/shell/open/command = "PATH_TO_PHP" -f "PATH_TO_SCRIPT" "%1" "%2" "%3" "%4" "%5" "%6" "%7" "%8" "%9"parameters.yml:parameters:ide_url: 'idea://%%%%f:%%%%l&/ PROJECT_PATH_ON_SERVER/> DRIVE_LETTER:/ PATH_ON_WINDOWS/'config.yml:framework:ide: '%ide_url%'PHP_SCRIPT_FILE:
<?php
function DoOutput($S)
{
//You might want to do something like output the error to a file or do an alert here
print $S;
}
if(!isset($argv[1]))
return DoOutput('File not given');
if(!preg_match('~^idea://(?:%25|%)?([a-z]:[/\\\\][^:]+):%?(\d+)/?$~i', $argv[1], $MatchData))
return DoOutput('Invalid format: '.$argv[1]);
$FilePath=$MatchData[1];
if(!file_exists($FilePath))
return DoOutput('Cannot find file: '.$FilePath);
$String='"C:\Program Files\JetBrains\IntelliJ IDEA 2018.1.6\bin\idea64.exe" --line '.$MatchData[2].' '.escapeshellarg($FilePath);
DoOutput($String);
shell_exec($String);
?>
41
« on: August 01, 2018, 10:01:31 pm »
I was surprised in my failure to find a script online to download all of an author’s stories from Fiction Press or Fan Fiction.Net, so I threw together the below. If you go to an author’s page in a browser (only tested in Chrome) it should have all of their stories, and you can run the following script in the console (F12) to grab them all. Their save name format is STORY_NAME_LINK_FORMAT - CHAPTER_NUMBER.html. It works as follows: - Gathers all of the names, chapter 1 links, and chapter counts for each story.
- Converts this information into a list of links it needs to download. The links are formed by using the chapter 1 link, and just replacing the chapter number.
- It then downloads all of the links to your current browser’s download folder.
Do note that chrome should prompt you to answer “This site is attempting to download multiple files”. So of course, say yes. The script is also designed to detect problems, which would happen if fictionpress changes their html formatting.
//Gather the story information
const Stories=[];
$('.mystories .stitle').each((Index, El) =>
Stories[Index]={Link:$(El).attr('href'), Name:$(El).text()}
);
$('.mystories .xgray').each((Index, El) =>
Stories[Index].NumChapters=/ - Chapters: (\d+) - /.exec($(El).text())[1]
);
//Get links to all stories
const LinkStart=document.location.protocol+'//'+document.location.host;
const AllLinks=[];
$.each(Stories, (_, Story) => {
if(typeof(Story.NumChapters)!=='string' || !/^\d+$/.test(Story.NumChapters))
return console.log('Bad number of chapters for: '+Story.Name);
const StoryParts=/^\/s\/(\d+)\/1\/(.*)$/.exec(Story.Link);
if(!StoryParts)
return console.log('Bad link format for stories: '+Story.Name);
for(let i=1; i<=Story.NumChapters; i++)
AllLinks.push([LinkStart+'/s/'+StoryParts[1]+'/'+i+'/'+StoryParts[2], StoryParts[2]+' - '+i+'.html']);
});
//Download all the links
$.each(AllLinks, (_, LinkInfo) =>
$('a').attr('download', LinkInfo[1]).attr('href', LinkInfo[0])[0].click()
);
jQuery('.blurb.group .heading a[href^="/works"]').map((_, El) => jQuery(El).text()).toArray().join('\n');
42
« on: October 14, 2017, 12:20:52 am »
A function to replace variables in a file that are in the format "VARIABLE_NAME=VARIABLE_DATA". Parameters are: VARIABLE_NAME VARIABLE_DATA FILE_NAME
function ReplaceVar() {
REPLACE_VAR_NAME="$1";
REPLACE_VAR_VAL=$(echo "$2" | perl -e '$V=<STDIN>; chomp($V); print quotemeta($V)' -);
perl -pi -e "s/(?<=$REPLACE_VAR_NAME[ \t]*=).*$/$REPLACE_VAR_VAL/" "$3"
}
The real difference between this script and normal command-line-Perl-regex-replaces is that it makes sure values are properly escaped for the search+replace regular expression.
43
« on: October 10, 2017, 06:35:19 pm »
The following is a simple bash script to ping a different domain once a second and log the output. By default, it pings #.castledragmire.com, where # is an incrementing number starting from 0. The script is written for Cygwin (See the PING_COMMAND variable at the top) but is very easily adaptable to Linux. The log output is: EPOCH_TIMESTAMP DOMAIN PING_OUTPUT
#This uses Window's native ping since the Cygwin ping is sorely lacking in options
#"-n 1"=Only runs once, "-w 3000"=Timeout after 3 seconds
#The grep strings are also directly tailored for Window's native ping
PING_COMMAND=$(
echo 'C:/Windows/System32/PING.EXE -n 1 -w 3000 $DOMAIN |';
echo 'grep -iP "^(Request timed out|Reply from|Ping request could not find)"';
)
i=0 #The subdomain counter
STARTTIME=`date +%s.%N` #This holds the timestamp of the end of the previous loop
#Infinite loop
while true
do
#Get the domain to run. This requires a domain that has a wildcard as a primary subdomain
DOMAIN="$i.castledragmire.com"
#Output the time, domain name, and ping output
echo `date +%s` "$DOMAIN" $(eval $PING_COMMAND)
#If less than a second has passed, sleep up to 1 second
ENDTIME=`date +%s.%N`
SLEEPTIME=$(echo "1 - ($ENDTIME - $STARTTIME)" | bc)
STARTTIME=$ENDTIME
if [ $(echo "$SLEEPTIME>0" | bc) -eq 1 ]; then
sleep $SLEEPTIME
STARTTIME=$(echo "$STARTTIME + $SLEEPTIME" | bc)
fi
#Increment the subdomain counter
let i+=1
done
44
« on: July 24, 2017, 12:00:18 pm »
I'm very sorry to everyone who has been waiting for me to get some updates done. I've just been super busy lately and getting to spend time on this project has just been impossible. I will be getting to it as soon as I can.
45
« on: July 07, 2017, 04:52:58 pm »
Most likely a database update  I'll take a look at it as soon as I have a chance. (Should be sometime in the next week)
Pages: 1 2 [3] 4 5 ... 38
|
|

