|
-
April 26, 2024, 08:59:37 pm

- Welcome, Guest
News:Official site launch very soon, hurrah!
Show Posts
This section allows you to view all posts made by this member. Note that you can only see posts made in areas you currently have access to.
Messages - Dakusan
526
« on: September 28, 2009, 05:30:54 am »
Oops, life kind of hit me like a ton of bricks the last few days and I haven’t had time to get much done. It didn’t help that I had a 72 hour straight run of wakefulness, then slept for about 24 hours straight :-). *Shakes fist at certain medications*. But now to continue on the second section of my previous medical post... Medical science has come a very long way in the last 100 years, making very large important jumps all the time, but there is still a very very long way to go. The “purpose” of the appendix was just “officially” found not too long ago, and if something that simple took that long to find out... But anyways, most of where we are in medicine still involves a lot of guessing and fuzzy logic. While we do know many things for certain, diagnosing is still more often than not guess work due to what the patient can describe. Even when we know what the problem is, we still aren’t even sure of the definite cause, and without that, we can only make educated guesses in how to treat them. Sometimes we even have the knowledge to diagnose a problem, but it may be too expensive, in a time+effort vs gains manner, or possibly too early in developmental stages and not considered proper yet. Then again, sometimes we even do have the answers but they are being withheld for “evil” purposes. Anyways, I have 4 stories I’d like to share today on this topic to drive my point home. First, I’ll get my own story out of the way. A couple of years back, my appendix burst, I assumed it was just my IBS, as stated in my previous post. Two days afterwards, I went to the doctor and we specifically said we wanted to rule out appendicitis as a cause, so they took my x-ray, and it somehow turned up as negative... so I was diagnosed with constipation, as my mother was often noting as what she thought it must be. So on the way out of the office, stepping out of the door, I stopped and asked the doctor if they could take a blood sample so I could see how my cholesterol was doing (been fighting high cholesterol for a long time, the medication I take for it works wonders), and they did. So I took some laxatives, and 3 days later I was still in lots of pain and lots of other problems. So the call from the doctor came in the middle of that Monday, having gone to the doctor mid-Friday, right before I was about to call them back, and I was instructed to go straight to the hospital, as my (white?) blood cell count was super high. Thank Thor I asked them. So I go to the hospital, they do a few tests, one involving drinking a liter of a liquid that tasted like chalk beforehand, which I had to do once on a return visit too, and they come back and tell me my appendix had burst, and somehow, miraculously, I wasn’t dead due to a pocket forming and containing the toxin, and I was to go into surgery within hours. Obviously, everything went relatively well, as I am still here. There was one really painful night, though, with a temperature so high that I was apparently hallucinating, and I don’t remember. So I got out of the hospital after a week... and then immediately went back in that night due to a bacteria infection and was on antibiotics for another week. At least I didn’t need morphine (ah gee...) that second week. On a more silly note, right before going into surgery, I jokingly asked my female surgeon how long it would take, as I had to log into my computer every (5?) hours for security or it would erase all my porn (or something like that). Well, the poor naive doctor took it seriously, and literally turned as red as an apple, at which point I had to rescind my statement and explain I was just joking ^_^;. Second story is much more recent. Can’t go into details, but a friend of mine was at the hospital with some stomach problems, and the doctors came back with congratulations, in that she was pregnant. After finally convincing them that she could not possibly be pregnant and was pretty sure she wasn’t carrying the reincarnation of Jesus, they did more tests and found out it was a rather nasty cyst in her (uterus?); good job doc(s)... so she had it removed. They determined very soon after when the bloodwork came back what type of cancer it was... so she’s been in very aggressive therapy since. The next story has been a long time upset of mine. A female cousin of mine, who has always been as sweet as can be, contracted lime disease. This in and of itself wouldn’t have been a problem normally, except that she and her parents had to go doctor hopping for well over a year to finally get it properly diagnosed. By this advanced stage of the problem, it was too late to be able treat it properly with no after effects, so she has lost most of the last 5+ years of her life to the disease and the incredible lethargy and problems it causes. They have been trying many many ways to cure the problem, and are finally hopeful at a new possible solution they’ve found. I hope to Thor it works out and she can start living her life to the fullest again; which actually parallels the next story quite well. I saved this one for last because it involves a celebrity :-). Scott Adams, creator/artist of the Dilbert comic strip, had been afflicted for a few years with Spasmodic Dysphonia, which causes an inability to speak in certain situations. After going through the prescribed medical procedure involving long needles several times per year for the rest of your life, he finally found a doctor who had a very large success rate of curing the illness, and it worked for him too. Apparently, the pharmaceutical industry shuts out any info they can about the proper treatment, as they make fists of money peddling out their very expensive temporary botox treatments that often don’t work well or at all. Long story short, our medical industry has a long way to go before I consider it a true science, the first step being saving it from the grip of the pharmaceutical giant. Scott Adam’s Blog Posts: Good News Day (October 24, 2006): Original Post, ArchiveAs regular readers of my blog know, I lost my voice about 18 monthsago. Permanently. It’s something exotic called Spasmodic Dysphonia.Essentially a part of the brain that controls speech just shuts down insome people, usually after you strain your voice during a bout withallergies (in my case) or some other sort of normal laryngitis. Ithappens to people in my age bracket. I asked my doctor – a specialist for this condition – how manypeople have ever gotten better. Answer: zero. While there’s no cure,painful Botox injections through the front of the neck and into thevocal cords can stop the spasms for a few months. That weakens themuscles that otherwise spasm, but your voice is breathy and weak. The weirdest part of this phenomenon is that speech is processed indifferent parts of the brain depending on the context. So people withthis problem can often sing but they can’t talk. In my case I could domy normal professional speaking to large crowds but I could barelywhisper and grunt off stage. And most people with this condition reportthey have the most trouble talking on the telephone or when there isbackground noise. I can speak normally alone, but not around others.That makes it sound like a social anxiety problem, but it’s really justa different context, because I could easily sing to those same people. I stopped getting the Botox shots because although they allowed meto talk for a few weeks, my voice was too weak for public speaking. Soat least until the fall speaking season ended, I chose to maximize myonstage voice at the expense of being able to speak in person. My family and friends have been great. They read my lips as bestthey can. They lean in to hear the whispers. They guess. They put upwith my six tries to say one word. And my personality is completelyaltered. My normal wittiness becomes slow and deliberate. And often,when it takes effort to speak a word intelligibly, the wrong word comesout because too much of my focus is on the effort of talking instead ofthe thinking of what to say. So a lot of the things that came out of mymouth frankly made no sense. To state the obvious, much of life’s pleasure is diminished when you can’t speak. It has been tough. But have I mentioned I’m an optimist? Just because no one has ever gotten better from Spasmodic Dysphoniabefore doesn’t mean I can’t be the first. So every day for months andmonths I tried new tricks to regain my voice. I visualized speakingcorrectly and repeatedly told myself I could (affirmations). I usedself hypnosis. I used voice therapy exercises. I spoke in higherpitches, or changing pitches. I observed when my voice worked best andwhen it was worst and looked for patterns. I tried speaking in foreignaccents. I tried “singing” some words that were especially hard. My theory was that the part of my brain responsible for normalspeech was still intact, but for some reason had become disconnectedfrom the neural pathways to my vocal cords. (That’s consistent with anyexpert’s best guess of what’s happening with Spasmodic Dysphonia. It’ssomewhat mysterious.) And so I reasoned that there was some way toremap that connection. All I needed to do was find the type of speakingor context most similar – but still different enough – from normalspeech that still worked. Once I could speak in that slightly differentcontext, I would continue to close the gap between thedifferent-context speech and normal speech until my neural pathwaysremapped. Well, that was my theory. But I’m no brain surgeon. The day before yesterday, while helping on a homework assignment, Inoticed I could speak perfectly in rhyme. Rhyme was a context I hadn’tconsidered. A poem isn’t singing and it isn’t regular talking. But forsome reason the context is just different enough from normal speechthat my brain handled it fine. Jack be nimble, Jack be quick.
Jack jumped over the candlestick. I repeated it dozens of times, partly because I could. It waseffortless, even though it was similar to regular speech. I enjoyedrepeating it, hearing the sound of my own voice working almostflawlessly. I longed for that sound, and the memory of normal speech.Perhaps the rhyme took me back to my own childhood too. Or maybe it’sjust plain catchy. I enjoyed repeating it more than I should have. Thensomething happened. My brain remapped. My speech returned. Not 100%, but close, like a car starting up on a cold winter night.And so I talked that night. A lot. And all the next day. A few times Ifelt my voice slipping away, so I repeated the nursery rhyme and tunedit back in. By the following night my voice was almost completelynormal. When I say my brain remapped, that’s the best description I have.During the worst of my voice problems, I would know in advance that Icouldn’t get a word out. It was if I could feel the lack of connectionbetween my brain and my vocal cords. But suddenly, yesterday, I feltthe connection again. It wasn’t just being able to speak, it wasKNOWING how. The knowing returned. I still don’t know if this is permanent. But I do know that for oneday I got to speak normally. And this is one of the happiest days of mylife. But enough about me. Leave me a comment telling me the happiestmoment of YOUR life. Keep it brief. Only good news today. I don’t wantto hear anything else.
Voice Update (January 14, 2007): Original Post, ArchiveNo jokes today on “serious Sunday.” Many of you asked about my voice. As I’ve explained in this blog,about two years ago I suddenly acquired a bizarre and exotic voiceproblem called a spasmodic dysphonia. I couldn’t speak for about 18months unless I was on stage doing my public speaking, or alone, orsinging. The rest of the time my vocal cords would clench and I couldbarely get out a word. Other people with this condition report the same bizarre symptoms.We can also often speak perfectly in funny British accents but not inour own voices. We can speak after we have laughed or yawned. Sometimesit helps to pinch our noses or cover our ears. I found I can talk okayif I stretch my head back and look at the ceiling or close my eyes. Andwe can all sing and hum just fine. It looks like a whacky mental problem, except that it comes onsuddenly and everyone has a similar set of symptoms regardless of theirpsychological situation at the time. (It’s not as if we all have postpartem depression or just got back from war.) The only widely-recognized treatment involves regular Botox shotsthrough the front of the neck and directly into the vocal cords. Butbecause the Botox takes some time to reach full impact, thenimmediately starts to wear off, you only have your best voice abouthalf of that time. And the shots themselves are no picnic. I was hopingfor a better solution, especially since I couldn’t do my publicspeaking after Botox injections because it weakened my voice too muchto project on stage. One day, long after the last Botox shot had worn off, I wasrepeating a nursery rhyme at home. I found that I could speak a poemfairly well even though I couldn’t speak a normal sentence. Suddenlysomething “clicked” in my brain and I could speak perfectly. Just likethat. It was amazing. [Note: I doubt the choice of poem had anything to do with it, but it was Jack Be Nimble.] Many of you asked if it lasted. It did last, for several days. ThenI got a cold, my throat got funky, I had to speak different because ofthe cold, and lost it. After the cold wore off, it took a few weeks toget back to my current “okay” voice. At the moment I can speak okay most of the time in quietconversation. In other words, if there is no background noise, I cantalk almost as if I never had the problem. That’s a HUGE improvementover the past. But I still can’t speak in noisy environments. That’s common withthis condition, and it has nothing to do with the need to speak loudlyto talk over the noise. It has something to do with the outside soundcoming into my brain and somehow disabling my speech function. If Icover my ears, I can speak almost normally. Unfortunately for me, the world is a noisy place. So outside ofconversations with my family at home, I still can’t have a normalconversation. Today I am flying to Los Angeles to spend a week with Dr. MortonCooper. He claims to be able to cure this problem completely – in manyif not most cases – using his own brand of intensive voice exercisesand feedback. I’ve communicated directly with several people who saythat he did indeed fix their voices. The medical community’s reactionto his decades of curing this problem is that they say each of hiscures is really just a case of a person who was misdiagnosed in thefirst place, since spasmodic dysphonia is incurable BY DEFINITION. Butmany of his cures have involved patients referred by the topspecialists in the field of spasmodic dysphonia. So if they are allmisdiagnosed, that would be a story in itself. Maybe I’m lucky enoughto be misdiagnosed too. I’m not sure how much blogging I will be able to do this week. I’lllet you know at the end of the week just how it went. It’s not a suddencure, and would involve continued voice exercises to speak in the"correct" way, but I am told to expect significant progress after aweek. Wish me luck.
Voice Update [2] (January 21, 2007): Original Post, ArchiveAsregular readers know, about two years ago I lost my ability to speak.The problem is called spasmodic dysphonia (SD). This update isprimarily for the benefit of the other people with SD. Many of youasked about my experience and for any advice. The rest of you will findthis post too detailed. Feel free to skip it. First, some background. There are two types of spasmodic dysphonia. Adductor: The vocal cords clench when you try to speak, causing a strangled sound. (That is my type.) Abductor: The vocal cords open when you try to speak, causing a breathy whisper. You can get more complete information, including hearing voiceclips, at the National Spasomodic Dysphonia Association (NSDA) website: http://www.dysphonia.org/ The NSDA site describes the two medical procedures that are recommended by medical doctors: 1. Botox injections to the vocal cords, several times per year for the rest of your life. 2. Surgery on the vocal cords – a process that only works sometimes and has the risks of surgery. What you won’t find at that site is information about Dr. MortonCooper’s method of treating spasmodic dysphonia, using what he callsDirect Voice Rehabilitation. I just spent a week with Dr. Cooper. Dr.Cooper has been reporting “cures” of this condition for 35 years. He’sa PH.d, not MD, and possibly the most famous voice doctor in the world. According to Dr. Cooper, the NSDA receives funding from Allergan,the company that sells Botox. Dr. Cooper alleges, in his newself-published book, CURING HOPELESS VOICES, that Allergan’s deeppockets control the information about spasmodic dysphonia, ensuringthat it is seen as a neurological condition with only one reliabletreatment: Botox. I have no opinion on that. I’m just telling you whatDr. Cooper says. Botox shots are expensive. Your health insurance would cover it, butI heard estimates that averaged around $2,500 per shot. I believe itdepends on the dose, and the dose varies for each individual. Eachperson receiving Botox for spasmodic dysphonia would need anywhere from4 to 12 shots per year. Worldwide, Dr. Cooper estimates that millionsof people have this condition. It’s big money. (The “official”estimates of people with SD are much lower. Dr. Cooper believes thoseestimates are way off.) I have no first-hand knowledge of Allergan’s motives or activities.I can tell you that Botox worked for me. But it only gave me a “good”voice about half of the time. Individual results vary widely. Evenindividual treatments vary widely. I think I had about 5 treatments.Two were great. Two were marginal. One didn’t seem to help much. Andthe shots themselves are highly unpleasant for some people (but notvery painful). I’ve heard stories of people who feel entirely happy with Botox. Forthem, it’s a godsend. And I’ve heard stories of people who had okayresults, like mine. Dr. Cooper says that people with the abductor typeof dysphonia can be made worse by Botox. I know one person with theabductor type who lost his voice completely after Botox, buttemporarily. Botox wears off on its own. It’s fairly safe in that sense. I can tell you that Dr. Cooper’s method worked for me, far betterthan Botox. (More on that later.) And you can see for yourself that theNSDA web site doesn’t mention Dr. Cooper’s methods as an option. Itdoesn’t even mention his methods as something that you should avoid.It’s conspicuous in its absence. Dr. Cooper claims that spasmodic dysphonia is not a neurologicalproblem as is claimed by the medical community. He claims that it iscaused by using the voice improperly until you essentially lose theability to speak correctly. Most people (including me) get spasmodicdysphonia after a bout with some sort of routine throat problem such asallergies or bronchitis. The routine problem causes you to strain yourvoice. By the time the routine problem is cleared up, you’ve solidifiedyour bad speaking habits and can’t find your way back. Dr. Cooper’smethods seek to teach you how to speak properly without any drugs orsurgery. Some people get spasmodic dysphonia without any obvious trigger. Inthose cases, the cause might be misuse of the voice over a long periodof time, or something yet undiscovered. Botox Versus Dr. Cooper
------------------------------- Botox worked for me. It was almost impossible for me to have aconversation, or speak on the phone, until I got my first Botox shot. But I had some complaints with the Botox-for-life method: 1. Botox made my voice functional, but not good. There was anunnatural breathiness to it, especially for the week or two after theshot. And the Botox wore off after several weeks, so there was always aperiod of poor voice until the next shot. 2. It looked as if I would need up to ten shots per year. That’s tenhalf days from my life each year, because of travel time. And the dreadof the shot itself was always with me. 3. The shots aren’t physically painful in any meaningful way. Butyou do spend about a minute with a needle through the front of yourthroat, poking around for the right (two) place in the back of yourthroat. Your urges to cough and swallow are sometimes overwhelming, andthat’s not something you want to do with a needle in your throat.(Other people – maybe most people – handle the shots without muchproblem.) 4. I couldn’t do public speaking with my “Botox voice.” It was tooweak to project on stage. People with spasmodic dysphonia can oftensing and act and do public speaking without symptoms. That was mysituation. Public speaking is a big part of my income. I used Botox to get through the “I do” part of my wedding in July of2006. Then I took a break from it to see if I could make any gainswithout it. My voice worsened predictably as the last Botox shot woreoff. But it stopped getting worse at a “sometimes okay, often bad”level that was still much better than the pre-Botox days. I could speak almost perfectly when alone. I could speak well enoughon stage. I could sing. About half of the time I could speak okay onthe phone. In quiet conversations I was okay most of the time. But Icould barely speak at all if there was any background noise. Do you know how often you need to talk in the presence of backgroundnoise? It’s often. And it wasn’t just a case of trying to speak overthe noise. There’s something mysterious about spasmodic dysphonia thatshuts off your ability to speak if there is background noise. As I wrote in a previous post, one day I was practicing my speakingwith a nursery rhyme at home. Something happened. My normal voicereturned. It happened suddenly, and it stuck. The media picked up thestory from my blog and suddenly it was national news. My voice stayed great until I caught a cold a few weeks later. Thecold changed my speaking pattern, and I regressed. With practice, Ibrought it back to the point where I could have quiet conversations.But I was still bedeviled by background noise and sometimes the phone.Despite my lingering problems, it was still amazing that anyone withspasmodic dysphonia would have that much of a spontaneous recovery.I’ve yet to hear of another case. But it wasn’t good enough. After the media flurry, I got a message from Dr. Cooper. He listenedto me on the phone, having an especially bad phone day, and he said hecould help. I listened to his spiel, about how it’s not really aneurological problem, that he’s been curing it for years, and that themedical community is in the pocket of Allergan. Dr. Cooper is what can be described as a “character.” He’s 75, has adeep, wonderful voice, and gives every impression of being a crackpotconspiracy theorist. His price was $5K per week, and he reckoned frommy phone voice that I needed at least a week of working with him, witha small group of other spasmodic dysphonia patients. Two weeks of workwould be better. (The hardcore cases take a month.) I would have to flyto LA and live in a nearby hotel for a week. So it’s an expensiveproposition unless you can get your insurance to pay for it. (Sometimesthey do if you have a referral from a neurologist.) Needless to say, I was skeptical. Dr. Cooper sent me his DVD thatshows patients before and after. I still wasn’t convinced. I asked forreferences. I spoke with a well-known celebrity who said Dr. Cooperhelped him. I heard by e-mail from some other people who said Dr.Cooper helped them. You can see video of before and after patients on his web site at: http://www.voice-doctor.com/ I figured, What the hell? I could afford it. I could find a week. If it didn’t work after a few days, I could go home. With Dr. Cooper’s permission, I will describe his theory and his treatment process as best I can. THEORY
------------ People with spasmodic dysphonia (SD) can’t hear their own voicesproperly. Their hearing is fine in general. The only exception is theirown voices. In particular, SD people think they are shouting when theyspeak in a normal voice. I confirmed that to be true with me. I neededthree other patients, Dr. Cooper, a recording of me in conversation,and my mother on the telephone to tell me that I wasn’t shouting when Ispeak normally. It has something to do with the fact that I hear my ownvoice through the bones in my head. In a crowded restaurant, if I speakin a voice to be heard across the table, I am positive it can be heardacross the entire restaurant. Most SD patients have this illusion. People with SD speak too low in the throat, because society gives usthe impression that a deep voice sounds better. Our deep voice becomesso much a part of our self image and identity that we resist speakingin the higher pitch that would allow us to speak perfectly. Moreover,DS people have a hugely difficult time maintaining speech at a highpitch because they can’t hear the difference between the higher andlower pitch. Again, this is not a general hearing problem, just aproblem with hearing your own voice. I confirmed that to be true withme. When I think I am speaking like a little girl, it sounds normalwhen played back on a recording. (People with abductor SD are sometimes the opposite. They speak attoo high a pitch and need to speak lower. That doesn’t seem to be asocietal identity thing as much as a bad habit.) Since SD people can’t “hear” themselves properly, they can’t speakproperly. It’s similar to the problem that deaf people have, but adifferent flavor. As a substitute for hearing yourself, Dr. Cooper’svoice rehabilitation therapy involves intensive practice until you can“feel” the right vibration in your face. You learn to recognize yourcorrect voice by feel instead of sound. People with SD breathe “backwards” when they talk. Instead ofexhaling normally while talking, our stomachs stiffen up and we stopbreathing. That provides no “gas for the car” as Dr. Cooper is fond ofsaying. You can’t talk unless air is coming out of your lungs. Iconfirmed this to be true for all four patients in my group. Each of usessentially stopped breathing when we tried to talk. The breathing issue explains to me why people with SD can oftensing, or in my case speak on stage. You naturally breathe differentlyin those situations. DR. COOPER’S METHOD
---------------------------------- He calls it Direct Voice Rehabilitation. I thought it was a fancymarketing way of saying “speech therapy,” but over time I came to agreethat it’s different enough to deserve its own name. Regular speech therapy – which I had already tried to some degree –uses some methods that Dr. Cooper regards as useless or even harmful.For example, a typical speech therapy exercise is to do the “glottalfry” in your throat, essentially a deep motorboat type of sound. Dr.Cooper teaches you to unlearn using that part of the throat forANYTHING because that’s where the problem is. Regular speech therapy also teaches you to practice the sounds thatgive you trouble. Dr. Cooper’s method involves changing the pitch andbreathing, and that automatically fixes your ability to say all sounds. To put it another way, regular speech therapy for SD involvespractice speaking with the “wrong” part of your throat, according toDr. Cooper. If true, this would explain why regular speech therapy iscompletely ineffective in treating SD. Dr. Cooper’s method involves these elements: 1. Learning to breathe correctly while speaking
2. Learning to speak at the right pitch
3. Learning to work around your illusion of your own voice.
4. Intense practice all day. While each of these things is individually easy, it’s surprisinglyhard to learn how to breathe, hit the right pitch, and think at thesame time. That’s why it takes anywhere from a week to a month ofintense practice to get it. Compare it to learning tennis, where you have to keep your eye onthe ball, use the right stroke, and have the right footwork.Individually, those processes are easy to learn. But it takes a longtime to do them all correctly at the same time. NUTS AND BOLTS
------------------------- I spent Monday through Friday, from 9 am to 2 pm at Dr. Cooper’soffice. Lunchtime was also used for practicing as a group in a noisyrestaurant environment. This level of intensity seemed important to me.For a solid week, I focused on speaking correctly all of the time. Idoubt it would be as effective to spend the same amount of time in onehour increments, because you would slip into bad habits too quickly inbetween sessions. Dr. Cooper started by showing us how we were breathing incorrectly.I don’t think any of us believed it until we literally put hands oneach others’ stomachs and observed. Sure enough, our stomachs didn’tcollapse as we spoke. So we all learned to breathe right, firstsilently, then while humming, and allowing our stomachs to relax on theexhale. The first two days we spent a few hours in our own rooms humminginto devices that showed our pitch. It’s easier to hum the right pitchthan to speak it, for some reason. The point of the humming was tolearn to “feel” the right pitch in the vibrations of our face. To findthe right pitch, you hum the first bar of the “Happy Birthday” song.You can also find it by saying “mm-hmm” in the way you would say ifagreeing with someone in a happy and upbeat way. The patients who had SD the longest literally couldn’t hum at first. But with lots of work, they started to get it. Dr. Cooper would pop in on each of us during practice and remind usof the basics. We’d try to talk, and he’d point out that our stomachsweren’t moving, or that our pitch was too low. Eventually I graduated to humming words at the right pitch. I didn’tsay the words, just hummed them. Then I graduated to hum-talking. Iwould hum briefly and then pronounce a word at the same pitch, as in: mmm-cow
mmm-horse
mmm-chair We had frequent group meetings where Dr. Cooper used a 1960s vintagerecorder to interview us and make us talk. This was an opportunity forus all to see each other’s progress and for him to reinforce thelessons and correct mistakes. And it was a confidence booster becauseany good sentences were met with group compliments. The confidencefactor can’t be discounted. There is something about knowing you can dosomething that makes it easier to do. And the positive feedback made ahuge difference. Likewise, seeing someone else’s progress made yourealize that you could do the same. When SD people talk, they often drop words, like a bad cell phoneconnection. So if an SD patient tries to say, “The baby has a ball,” itmight sound like “The b---y –as a –all.” Dr. Cooper had two tricks forfixing that, in addition to the breathing and higher pitch, which takescare of most of it. One trick is to up-talk the problem words, meaning to raise yourpitch on the syllables you would normally drop your pitch on. In yourhead, it sounds wrong, but to others, it sounds about right. Forexample, with the word “baby” I would normally drop down in pitch fromthe first b to the second, and that would cause my problem. But if Ispeak it as though the entire word goes up in pitch, it comes out okay,as long as I also breathe correctly. Another trick is humming into the problem words as if you arethinking. So when I have trouble ordering a Diet Coke (Diet is hard tosay), instead I can say, “I’ll have a mmm-Diet Coke.” It looks like I’mjust pausing to think. Dr. Cooper invented what he calls the “C Spot” method for findingthe right vocal pitch. You put two fingers on your stomach, just belowthe breastbone, and talk while pressing it quickly and repeatedly, likea fast Morse code operator. It sort of tickles, sort of relaxes you,sort of changes your breathing, and makes you sound like you aresitting on a washing machine, e.g. uh-uh-uh-uh. But it helps you findyour right pitch. Dr. Cooper repeats himself a lot. (If any of his patients arereading this, they are laughing at my understatement.) At first itseems nutty. Eventually you realize that he’s using a Rasputin-likeapproach to drill these simple concepts into you via repetition. Ican’t begin to tell you how many times he repeated the advice to speakhigher and breathe right, each time as if it was the first. Eventually we patients were telling each other to keep our pitchesup, or down. The peer influence and the continuous feedback wereessential, as were the forays into the noisy real world to practice.Normal speech therapy won’t give you that. Toward the end of the week we were encouraged to make phone callsand practice on the phone. For people with SD, talking on the phone isvirtually impossible. I could speak flawlessly on the phone by the endof the week. RESULTS
------------- During my week, there were three other patients with SD in thegroup. Three of us had the adductor type and one had abductor. Onepatient had SD for 30 years, another for 18, one for 3 years, and I hadit for 2. The patients who had it the longest were recommended for aone month stay, but only one could afford the time to do it. The patient with SD for 3 years had the abductor type and spoke in ahigh, garbled voice. His goal was to speak at a lower pitch, and by theend of the week he could do it, albeit with some concentration. It wasa huge improvement. The patient with SD for 30 years learned to speak perfectly whenevershe kept her pitch high. But after only one week of training, shecouldn’t summon that pitch and keep it all the time. I would say shehad a 25% improvement in a week. That tracked with Dr. Cooper’sexpectations from the start. The patient with SD for 18 years could barely speak above a hoarsewhisper at the beginning of the week. By the end of the week she couldoften produce normal words. I’d say she was at least 25% better. Shecould have benefited from another three weeks. I went from being unable to speak in noisy environments to beingable to communicate fairly well as long as I keep my pitch high. Andwhen I slip, I can identify exactly what I did wrong. I don’t know howto put a percentage improvement on my case, but the difference is lifechanging. I expect continued improvement with practice, now that I havethe method down. I still have trouble judging my own volume and pitchfrom the sound, but I know what it “feels” like to do it right. Dr. Cooper claims decades of “cures” for allegedly incurable SD, andoffers plenty of documentation to support the claim, including video ofbefore-and-afters, and peer reviewed papers. I am not qualified tojudge what is a cure and what is an improvement or a workaround. Butfrom my experience, it produces results. If SD is a neurological problem, it’s hard to explain why people canrecover just by talking differently. It’s also hard to understand howbronchitis causes that neurological problem in the first place. Sowhile I am not qualified to judge Dr. Cooper’s theories, they do passthe sniff test with flying colors. And remember that nursery rhyme that seemed to help me the firsttime? Guess what pitch I repeated it in. It was higher than normal. I hope this information helps.
527
« on: September 28, 2009, 05:30:53 am »
So I just now made the ~200 mile drive from Austin (my current residence) to Dallas (where I grew up), both Texas of course, to take care of some stuff. I’ll be driving back tonight, wee. I have to say, that particular drive is one of the dullest in existence. It’s not particularly long, traffic is normal, and nothing special per say, there’s just nothing to look at the whole way, And large gaps of road with no stops in between. At least in the desert or middle states you have a little variety or mountains hopefully to look at. I’ve made 24+ hour straight trips back and forth from Canada that I’ve loathed less :-). Anywho, whenever I’m on a car trip of more than 100 miles, my mind always turns to counting down miles and running simple arithmetic in my head to calculate how much longer it will take at my current speed to reach my destination, how much time I can cut off if I went faster, etc. This time around my mind turned towards deriving some formulas. This is not the first time this has happened either XD. I have to occupy myself with something when there’s just music to listen to and nothing else to do! Driving is basically a muscle reflex for me on these long drives. So there are 2 formulas that are useful for this situation. #1 How much faster you are traveling per minute at different speeds. #2 How much time you will save at different speeds. Variables: H=Higher Speed In MPH
L=Lower Speed In MPH
M=Number of miles to travel The following are basic proofs of how the formulas work. God... I swore after I got out of geometry I’d never think about proofs again. The first one is very simple. Number of extra miles traveled per hour = (H-L)
Number of extra miles traveled per minute = (H-L) mph / 60 minutes So, for example, if you increase your speed from 20 to 30, you are going 10 miles an hour faster, which is 1/6 of a mile a minute. The second one is slightly more difficult but much more useful. h = Time it takes in hours to travel M at H = M miles / H mph
l = Time it takes in hours to travel M at L = M miles / L mph
Difference of time it takes between 2 speeds in hours = h-l
(M/H)-(M/L) [Substituting variables]
(MH-ML)/(HL) [Getting a common denominator]
M*(H-L)/(HL) [Distributive property] So we can see that time saved, in hours, per mile is (H-L)/(H*L). Just multiply that by M to get total time saved in hours. With this second formula, we can see that in the higher speeds you go, the difference between the two speeds increase geometrically to get the same type of time savings (because H*L is a divisor, making it inversely proportional). For example: If H=20 mph and L=10mph
Time saved = (20-10)/(20*10) = 10/200 = 1/20 of an hour saved per mile, or 3 minutes
If H=30 mph and L=20mph
Time saved = (30-20)/(30*20) = 10/600 = 1/60 of an hour saved per mile, or 1 minute If you wanted to save 3 minutes per mile when starting at 15 mph... (x-15)/(15x)=1/20
x-15=15x/20
-15=15x/20-x
-15=-1/4x
x=60 miles per hour If you wanted to save 3 minutes per mile when starting at 20 mph... (x-20)/(20x)=1/20
-20=20x/20-x
-20=0 ... Wait, what? ... oh right, you cant save 3 minutes when it only takes 3 minutes per mile @ 20 mph, hehe. And if you wanted to save 6 minutes starting at 20mph, you would have to go -20mph, which is kind of theoretically possible since physics has negative velocities... just not negative speeds >.>. I’m sure all it would take is one point twenty one jiggawatts to achieve. If you’ve actually read this far without getting bored, I congratulate you :-). Even more sad is the last Dallas-Austin drive I made in which I couldn’t remember the compound continually interest formula and spent a good chunk of the time deriving it in my head (all I could remember was the needed variables “pert” - principle, e (~2.71 - exp), rate, time).
528
« on: September 28, 2009, 05:30:52 am »
OK, so I lied last time and am not doing the second half of my medical stuff post like planned, and will save that for later. I should be posting happy stuff on a supposed-to-be-happy day like today anyways ^_^;. Most of you out there who have heard of Gainax know of it due to Neon Genesis Evangelion (better known, and hereby referred to, as Eva), their “ground breaking” series released in ‘95-‘96. I’d have to say this was, and may still be, the most well known good anime series, meaning not including such tripe as Dragon Ball Z, Pokemon, Digimon, Sailor Moon (which isn’t THAT bad actually...), etc. It always gave me a bad tremble whenever I mentioned anime to general people and they replied with “oh, you mean (like) Sailor Moon?” But anyways... I should let you know beforehand, most of this post is a history of anime and some interesting info on the anime Nadia. The TV series Gainax did immediately before Eva, Nadia: Secret of the Blue Water, released in ‘89-‘91, is one of, if not my favorite anime series. You can definitely see the influence it had on Eva too. Before I talk about Nadia though, a little history about Gainax first. If anyone is really interested, check out their OVA (Original Video Animation) “Otaku no Video” release in ’91, which is KIND OF an autobiographical parody. I just picked up a copy for myself with some of the Chanukah/Xmas I received this year ^_^. Basically, Gainax is made up of a bunch of otaku. So these anime otaku in the mid ‘80s were of the mindset of “man, we can do better than all the shit that’s coming out”, so they started their own “amateur” company of fervent obsessed fans, and revolutionized the industry with their brilliance. A good chunk of what they do is worth a watch, though I am not quite a fan of all their stuff, it all has its own fun nuances and radiance to it that can only be found by people that truly love what they are doing. So, back to Nadia. I’d rather not really go into the story because I don’t want to ruin anything for anyone that may choose to watch it, but it is heavily based around Jules Verne’s works, most specifically around Twenty Thousand Leagues Under the Sea and the exploits of Captain Nemo, though with the usual crazy Japanese anime twist. It takes place in 1889-1890 and has a very steam punk feel to it. Disney’s 2001 Atlantis: The Lost Empire is actually quite a blatant rip of Nadia too, and not even an iota as worth it, IMO. I have also heard The Lion King was a pretty blatant rip of Kimba the White Lion, an anime from the mid 1960s. I cannot personally confirm this however, and can’t complain much as The Lion King is one of my two favorite Disney movies, along with Aladdin. But um... back to the topic on hand... darn tangents!! Nadia weaves many different genres very excellently into its story including science fiction, adventure, mystery, comedy, and a hint of romance, but maintains its silly mood throughout, even when dealing with clichéd “difficult” topics like killing, death, and general genocide :-). The main characters are Nadia and Jean, an engineering genius Frenchman, who are excellent foils for each other. One example is how Nadia is one of those “dear god how can you possibly even think about eating a dead animal” vegetarians, which Jean just can’t comprehend “what are you talking about, it’s meat”. And then you bring in the well-mannered 4 year old Marie who is always complaining about how immature/ill mannered the adults are... it’s just a very fun series with a lot of memorable and lovable characters. So after finishing the ~40 episodes over a week, I went and checked the Wikipedia article on it and found some very fascinating facts, namely tying in Miyazaki with the series, which was a shocker too me. Hayao Miyazaki is by far my most respected (anime?) director, I believe. Most people would know of his works under the anime studio Studio Ghibli, though he doesn’t only do stuff for them, and they have other directors too, but Ghibli and Miyazaki are generally pretty synonymous. I have multiple other topics written down on Miyazaki that I will talk about later, and will post a good list of Miyazaki/Ghibli titles I made a while ago as soon as I can find it. Anyways, some of the more interesting trivia notes I stole from Wikipedia are as follows: - This show’s origins date back to the mid-1970s when Hayao Miyazaki was hired by Japanese movie giant Toho to develop ideas for television series. One of these concepts was "Around the World Under the Sea", (adapted from Jules Verne’s Twenty Thousand Leagues Under the Sea), in which two orphan children pursued by villains team up with Captain Nemo and the Nautilus. It was never produced, but Toho retained the rights for the story outline. This explains why Anime fans often liken Nadia to a Miyazaki production; the animator reused elements from his original concept in later projects of his, notably the Sci-Fi series Future Boy Conan and his action-adventure film Castle in the Sky.
- Approximately ten years later, Gainax was appointed by Toho in 1989 to produce a TV series which would be broadcast on the Japanese educational network NHK. Miyazaki’s outline for "Around the World Under the Sea" was the one which captivated Gainax the most. Under the direction of Hideaki Anno, the animation studio took the central story and setup Miyazaki had developed and touched it up with their own creativity. (incidentally, Anno had previously worked for Miyazaki as an animator on Nausicaä of the Valley of the Wind.)
- Nadia showed up on the Japanese Animage polls as favorite Anime heroine, dethroning the then top champion, Hayao Miyazaki’s Nausicaa.
- Nadia was originally intended to have an estimated 30 episodes. Since the show was so popular in Japan, however, NHK requested Gainax to produce more episodes, extending the episode count to 39. These episodes, dubbed as the "infamous island episodes" (which begin on Episode 23 and conclude on Episode 34), took hits for poor animation (since, as mentioned, other animation studios in Japan and Korea produced these episodes), ill-conceived plotting, and character stupidities; consequently, they drove many fans away. Only by Episodes 35-39 does the show return to its initial roots wherein lies its appeal. The setting of these episodes was suggested by Jules Verne’s other novel featuring Captain Nemo, Mysterious Island.
- According to the notes found in the DVD sleeve of the Italian edition, the true reason behind the difference between the "infamous island episodes" and the rest of the series, would be that production was late on schedule. Starting with episode 11, Anno was working up to 18 hours a day on the series, and yet he was unable to cope with the screenplay, which was then handed to the storyboard team. After episode 20 (aired September 21, 1990), NHK put Nadia on hold to make space for news coverage on the Gulf War: the series returned about a month later with episode 21 (aired on October 26th). Nonetheless production was still late, and Anno asked friend and Gainax co-founder Shinji Higuchi to take over the direction of the series, while he was going to focus on the ending. According to the same source, Anno would have stated that episodes 30 and 31 were the only he would have saved among the Island Chapter ones, while episode 34 was entirely scrapped and replaced by edited sequences of previous episodes.
- At the start of each episode, a Japanese inscription appears on screen (written in the Latin alphabet) and is read by a man’s voice challenging the viewer to follow him for an adventure. "Are you adventurers? Do you seek the truth behind the mythical being that lies beneath the blue waterfalls named The Perilous. If you are, then you must first find me." This derives from the perplexing challenge of Arne Saknussemm in Verne’s Journey to the Center of the Earth.
- The series contains numerous nods to other Japanese television series, as is to be expected in a series by Gainax, which is famously comprised of "otaku" (fervent anime fans). Ostensibly, the Grandis Gang are modeled after the villains from Tatsunoko’s Time Bokan series, and M78, the home system of the Atlanteans, is also the home of Tsuburaya’s Ultraman.
- In the Star Trek: The Next Generation Technical Manual, authors Michael Okuda and Rick Sternbach state that the superconducting crystals used in Starfleet phasers are called fushigi no umi. Sternbach is a noted fan of anime.
One of the most important notes here is the forth and fifth bullets talking about the “infamous island episodes”. While they are still in the general Nadia style, and are fun, they have their downsides. I would personally even recommend skipping at least one and a half of these episodes, due to them being so worthless. They are: - A large chunk of #26 “King’s on his Own” - After Jean gets knocked out after a terribly silly Wile E. Coyote falling gag homage and he dreams of inventing 21st century technologies.
- Most, if not all, of #34 “Love to Nadia”, which is a “singing recap” episode. What I remember of the songs are especially atrocious.
On that note, the movie really isn’t worth watching at all either. Especially the first 1/3 (30 minutes) of the movie, as it is nothing but a recap of the series. Oh, also, the original title was translated as “Nadia of the Mysterious Seas”.
529
« on: September 28, 2009, 05:30:51 am »
[8/2008] I’ve been bullied into removing this post for the time being until I get it rewritten  . Annoying too, as it was my most in depth and, I believe, longest post, at more than 2500 words.
530
« on: September 28, 2009, 05:30:50 am »
It’s great to have standards so everything can play together nicely. I’ve even heard IE8 should pass the Acid2 test with “Web Standard Compatibility” mode turned on, and it has been confirmed for a long time that FireFox3 will (finally) pass it. Microsoft, of course, has a bit of a problem with backwards compatibility when everyone had to use hacks in the past to “conform” to their old IE software, which was, and still is, filled with bugs and errors; and with IE version upgrades, they need to not break those old websites. This really technically shouldn’t be a problem if people properly mark their web pages with compatible versions of HTML, XHTML, etc, but who wants to deal with that? Compatibility testing and marking, especially in the web world, is a serious pain in the ass, which I can attest to after working with web site creation for many years, something I am not very proud of :-). I am a C++ advocate, and Java/.NET hater, and yes, I’ve worked heavily in all of them. Anyways, some new web standards even break old ones, for example: <font><center></font></center> is no longer allowed. Non nested (ending child elements before the parent) is no longer possible in certain circumstances in HTML4, and definitely not allowed in XHTML, as that would be specifically against what XML was designed for. This was one of my favorite parts of original HTML too, in that you could easily combine formatting elements in different sections and orders without having to redefine all previous formats each time. Though CSS does help with this, it has its own quirks too that I consider to be a rather large failing in its design. I should be expanding more on that later on. And then there’s this one other oddity that has always bugged me. Two standard HTML colors are “gray” and “lightgrey”... if that’s not a little confusing... and for the record, “grey” and “lightgray” do not work in IE. Further, XML, while it has its place and reasons, really really bugs me. Just the fact that it really slows things up and is overused where it’s not needed because it is the “popular” thing to do. Come on people, is it that hard to create and use interfaces for binary compiled data? Or even ini-type files for crying out loud... Until we have specific hardware designed and implemented to parse XML, or better text parsing in general, I will continue to consider XML a step backwards, a very unfortunate reoccurring reality in the software world.
531
« on: September 28, 2009, 05:30:49 am »
I read through Eragon and Eldest, the first two books of the Inheritance Cycle, by Christopher Paolini, a while back, and was very happy with the novels, mainly for the relationship between the two protagonists, Eragon and his dragon Saphira. The fantasy novels brought in a bunch of new possibilities of fun with dragon lore and their abilities, a topic which has, to my knowledge, never really been elaborated or expanded on in the past to this kind of extent, though I have heard the lores in these books bears a large resemblance to a novel called Dragonriders of Pern. I would recommend the Inheritance Cycle to anyone looking for a fun, though not necessarily quick, fantasy read. The series was originally supposed to be three novels, but as of a few months ago it was announced that it would be four. The third book should be coming out in September of next year, which I am waiting in anticipation for, though nowhere near the level of excitement as any of the Harry Potter books brought me. The reason for this post though is to actually rant about the movie adaptation. One pet peeve of mine is people that say movies or TV shows are horrible without ever having given them a viewing, let alone a chance. I am the kind of person that will usually sit through anything, no matter how bad I feel it is, just so I can talk to people about it afterwards and be able to validly say why I did or did not enjoy it. This, however, did not apply to the Eragon movie. I was retching after about three minutes and think I got through five to ten minutes before I was so thoroughly disgusted I had to stop and just fast forward through the rest to see different parts I was curious about. Which was a mistake as the rest was even worse than the beginning. It was that bad. The movie was very obviously a ploy by the studios to milk in some money by throwing out a half baked fantasy movie trying to parallel Lord of the Rings in style. I honestly don’t know how it got as far as it did. I went to do some research and found out the director, Stefen Fangmeier, who had mainly been a visual effects guy in the industry, had no prior experience as a primary director, and only one as a secondary director, and was about as suited to the job as Bush Jr. would be to playing Jeopardy. What’s even worse is who wrote the screenplay, Peter Buchman, who’s only previous screenplay work had been... get this... Jurassic Park 3. I’m not even going to go there. I really have to wonder how the hell those 2 got ahold of the license to make the movie. The book was, after all, a New York Times #1 seller. The publishers must have really dropped the ball on this one, or maybe Paolini, being pretty much still a kid by the time he finished the first novel (19), somehow got taken advantage of. I just find the situation to be horribly sad. It probably didn’t help that I didn’t expect much at all from the movie as I had heard about its huge flop after opening, with many dedicated fans of the novels walking out of the theater in tears of disappointment. On another slightly-related note, it has been rumored as of today that it is now official that Peter Jackson will be producing 2 Hobbit movies. We shall see, but I would be very happy if it was true. I thought Jackson did the best possible job that could have been done on the movies. I only had one major complaint, in that Gimli was really given a short end of the stick throughout them, though at least they picked John-Rhys who was perfect for the part. Gimli was one of my favorite characters in the novels, and they substituted any of his glory to his pretty-boy counterpart elf, Legolas. I also had a few minor quibbles with it, including some scenes I had wished to have seen (ie Bombadil), but were left out for obvious reasons, and that they changed around bits of the story so some actors would get more screen time and they wouldn’t have to introduce others, like Arwen stealing roles of multiple other elves. Alas. The thing I liked most about them was how well the CG was integrated with the live action shooting. I still consider it the best job done integrating CG into a movie I’ve seen; so well that you can no longer tell that it’s clearly computer generated.
532
« on: September 28, 2009, 05:30:48 am »
I’ve been a long time fan and user of Seagate hard drives, as they are the only brand that have consistently not failed me, like Maxtor, Western Digital, and others. The first Seagate drive that I ever had die on me was almost 10 years after its first use. This trend seems to however not follow to its FreeAgent external USB drive line. I was a bit iffy on trying them out, as I had read online before buying that they had a seemingly high failure rate on arrival. Low and behold, I ended up buying one from Office Depot around Thanksgiving, as $100 for 500 gigs seemed well worth it, and it was dead on arrival. I think it ended up passing maybe 1 out of 5 trial formats. So I swapped it out, tried another, and it was DOA too, passing its format and scandisk, but then failing out on multiple sectors when I tried to use it (I am super obsessive about data integrity). So I gave up on those. My fears since I had heard that Seagate bought out Maxtor, the probably lowest quality hard drives on market, had been confirmed, though probably for different reasons. I did however recently buy a new SATA Seagate 500 gigger @ ~$100 and it seems to be working fine ^_^. Random Trivia: Gigabyte is actually technically supposed to be pronounced “jigga-byte” as in jiggawatt from the Back to the Future movie(s). The suffix has just been mispronounced for so long, no one seems to know that Back to the Future actually had it right :-). I found this out after watching a video from the early 80s on hard drives, and then confirming from multiple dictionaries and sources.
533
« on: September 28, 2009, 05:30:47 am »
So I’ve been rewatching lots of old shows over the past few years that I watched as a kid and remember enjoying. The latest reinstallment of this pattern would be Disney’s Gargoyles. It’s still a lot of fun to watch even though the antagonists’ plots are a little... unbelievable sometimes :-). The main reason I wanted to mention it though was the fact that it has a plethora of star trek actors, mostly from Next Generation, showing up in it. Hearing familiar voices I recognize always makes me smile, especially when put to animated characters. The ones I’ve recognized so far are: | Actor Name | Gargoyles Role | Star Trek Role |
|---|
| Jonathan Frakes | Xanatos (Main antagonist) | Will Riker | | Marina Sirtis | Demona | Deanna Troi | | Michael Dorn | ColdSteel (One of Goliath’s rookery brothers) + Tarus in “The New Olympians” | Worf | | Brent Spiner | Puck (Yes, Oberon/Titania’s fairy) | Data | | Nichelle Nichols | Diane Maza (Female Cop’s mother) | Uhura (OST) | | Colm Meaney | Mr. Dugan in “The Hound of Ulster” | Miles O’Brien | | Kate Mulgrew | Titania & Anastasia (Fox’s Mother) | Katherine Janeway | | Avery Brooks | Nokkar in “Sentinel” (Digitally enhanced) | Benjamin Sisko | | LeVar Burton | Anansi the spider in “Mark of the Panther” (Digitally enhanced) | Geordi LaForge | | John Rhys-Davies | MacBeth | Leonardo Da Vinci (Voyager... hey, he counts for Star Trek!! XD) |
But of course, many of these actors have played dozens to hundreds of other rolls and deserve to be known for more than just Star Trek, including recently Nichelle Nichols on Heroes, right after George Takei (Sulu) left the stage. If you haven’t ever seen any of Takei’s stand up, I would like to note it’s good stuff, and that he has a wonderful sense of humor. On another note, John Rhys has always been one of my favorite actors too. He’s been in more things than you could shake a stick at, and you probably wouldn’t have even realized about half of them. Most people nowadays would most readily recognize him as Gimli from the Lord of the Rings movies. One other recent smile came during rewatching DuckTales. I’m sure anyone of my age group that watched the show will remember the Golden Goose episodes. I had just noticed on a recent rewatching of the series that when the mystical water is used to turn things back from gold, it uses the lightsaber activation sound :-).
534
« on: September 28, 2009, 05:30:46 am »
Hi all, It has now been well over a year since I started working on this web site, and it’s still not even remotely completed. I wanted to have everything finished before a launch, but I realized long ago that would not happen, as there is too much I want from this site, so I will be launching as soon as I can, and updating sections as I go. I had gotten a great deal of it done the first month or two that I had started on it in October of 2006, but then real life kicked in and I lost track of it, and haven’t really touched it since. Many of the upcoming posts in the near future will be ‘retro posts’ in which I formed the idea sometime in the last year, and jotted down the basic premise to write about more fully later. I’ll probably be keeping most of my posts geared towards technical stuff, though I am also trying to get most of the non technical stuff out of the way first, too, and I’ll try to update 3-4 times a week, in an every-other day type of schedule, more often if I feel like it or am inspired, as soon as the site is launched.
535
« on: September 28, 2009, 05:30:45 am »
I’ve been a Star Trek fan for as long as I can remember... which goes back to at least the age of 3. One of my first memories is watching the live airing of a Star Trek The Next Generation (STTNG) episode in which a parasitic alien race, very much like the Goa’uld that come much later in Stargate, tries to take over Star Fleet. I’ve religiously watched STTNG, Deep Space 9 (DS9), and Voyager through the years, and quit at that point with much animosity towards Enterprise and Star Trek: Nemesis. Anyways, let’s get to the point of this post. I have recently started watching the 3 seasons of The Original Star Trek (TOS). My only impressions before this had been made up by seeing a random episode or two over the years, which screamed campiness to me. I can honestly now say though, after getting through a number of episodes, it’s still, after so many years, quite fun. And that’s saying something, as old stuff usually seems crappy unless you have nostalgia towards it. The 2 things I respected most about STTNG and future co-spinoffs, for as long as they held it... was that they TRIED to maintain a proper continuity starting with STTNG. At the beginning, it was rare that they ever contradicted themselves, but as the legacy grew, the inconsistencies started becoming ridiculous. This has been my opinion for many years, and now that I am watching through TOS, I can finally see how bad it can really get (well, to be honest, I think Enterprise went way beyond anything in this regard, but I didn’t watch enough of it to talk about it in an informed manner. I will only talk about thing’s I’ve seen enough of to bash, and yes, I have gone through a lot of crap purposely for this reason...). It is actually quite good, however, that STTNG disregarded quite a bit of the original canon because it would have ruined the universe in a manner. For example, in one of the first episodes of TOS, they traveled back in time by no special means other than pushing their engines faster than warp X. There was another early episode where they had fully functioning androids and the (slightly abused) machinery that created them (contradicting Data of STTNG). These are just two of many other “large” cans of worms they opened up by being too “open ended”. However, the producers made the right decision, IMO, and scrapped all the canon from TOS that they wanted and only made reference to it when they felt like it, starting the true canon of the Star Trek universe with Jean-Luk and his crew all the way through the end of DS9 and Voyager. I am still very anxious to continue watching TOS but time has been very constrained lately and my multitasking abilities have diminished significantly over the years... a large part I’m sure from medications I take (such as for ADD or whatnot...). On another random point about the Star Trek universe, while watching TOS, I found myself really enjoying the short costumes on all the female characters. I myself am quite the feminist, so this would usually go against my views, but for some reason, it fits real well and makes it more of a... shall I put it... fun/less serious atmosphere ^_^;. They tried to carry this legacy over to STTNG with Diana Troy in her “relatively skimpy” outfit(s), but they really did not do a good job of it. It just did not fit, at all. There was a specific episode were Picard is forced to leave the ship (to find some Romulan device that he has specific knowledge of due to a senior thesis or something), and another captain takes over. It raised my eyebrow when he harshly ordered Diana to put on a proper uniform, but he was completely right in doing so. I believe this might have been the producers/directors attempt at commenting on the issue. The final thing I noticed that I wanted to comment on was just a little giggle for me. In the very first episode of TOS (with Shatner, not counting “The Cage” pilot with Pike) in which a crewman gains god-like powers, he creates/materializes a grave for Kirk, which reads “James R. Kirk” - which as we all know, Kirk was given the middle name of “Tiberius”, as he is often cited as “James T. Kirk” .... Just one of those minor continuity things that you wonder why they hadn’t caught it at the time... or maybe they decided to ignore it and still go with “Tiberius” as it is a pretty cool middle name. Anyways, Star Trek (OST, STTNG, DS9, Voyager) & Star Gate (Seasons 1-7) are all very good stuff that do not date too badly on social issues. For anyone open to checking out new stuff who hasn’t tried watching either of these (is that possible that anyone hasn’t ever been exposed to at least one Star Trek series?), they are well worth it.
536
« on: September 28, 2009, 05:30:44 am »
I figure near the beginning of this blog (which I will never call this section a blog beyond this point as it gives an inappropriate connotation for what I am trying to do with this site...), I should mention a little bit about myself and my personality. For starters, my name is Jeffrey Riaboy, and I’ve gone by the handle Dakusan for many many years. I’m currently a 25 year old male [I edit this one post and try to keep it up to date] who is mostly freelance, but I hold some steady contract jobs, none of which I can really talk about. I am a 100% self taught programmer/computer scientist/engineer, hacker/reverse engineer, computer repair expert, network engineer, server administrator, etc... [computer] nerd. I spend most of my life and time on computers, though I do get around socially with my small clique of friends :-). My 2 main purposes for this site are to inform people who wish to listen of my learning experiences and discoveries which I find worthy to share, and to get a good archive up of all my life’s work. I will be trying to keep most of the posts here more towards a computer/technical nature, as I assume that is why anyone visiting this site would be here, but I always have a lot to talk about on other topics so there will be a lot of other stuff too, sorry ^_^;. These non-technical posts will much more frequent the beginnings of my archives so I can get them out of the way. I have a... rather large... backlog list of topics to talk about. You will find out in the posts to come that I like to poke at things and complain about problems which should be fixed. I spend a large amount of my time making sure everything is working right for a great many people in many ways, and I wish other people would do the same for others and their projects. This is why I vent/rant. Sure, I could get involved in every [open source] project that I like and spearhead the things I see as weaknesses, but alas, there are only so many hours in a day. You will also find I am quite blatant and honest to a T on anything I discuss. I take this personality quirk IRL to an extreme too, which often gets me in trouble :-). I try to program as often as possible in C/C++. My favorite aspect of programming is optimization and getting things to work as fast and as best as they can. Unfortunately, a large part of programming [in the “real world”] is engineering the code so that anyone could jump in and work with it; so code layout/design and my personal syntax style are also large on the priority list these days. I dabble in most all the other mainstream computer languages too. I highly subscribe to “the right tool for the job” philosophy. Which fortunately 99% of the time can keep me away from such travesties as .NET and Java! I work every now and then on “quickies” in VB and PHP. I also work a little too much in JavaScript and Flash (and PHP of course, but I enjoy it in a way), which have become necessities due to the web being such a large market these days. One of my first big projects was my NES emulator, Hynes. Unfortunately, the emulation community at that time was full of a lot of strife (this was right after the UltraHLE release of 99). Due to my fear of my project being misused and released with a Trojan, I never really got into the open source community. (I now look back at that and wonder why I was so worried... of course, that was before the open source community was really mainstream too)... I am trying to remedy this though and am going back and fixing up all my old projects for release on the web as time permits, which unfortunately, means this will take a very long time :-). Anyways, I think this pretty much lets you know what this site is for now, who I am, and what to expect. I hope I can keep you interested ^_^. Enjoy. P.S. You might also notice, which can often be a bad thing, that when I write stuff, I type ALOT. Mostly because I talk online how I talk IRL... bleh. P.P.S. You may have noticed a long gap between the first post and this one, and many subsequent ones. That is because after making the first post, I decided I needed to build up a real website to host everything, and make it a “big” project. So, further content was put on hold while I worked up everything needed for the launch, and life continued between other posts after that too :-).
537
« on: September 28, 2009, 05:30:43 am »
A few days ago I threw together a script for a friend in GreaseMonkey (a FireFox extension) that removes the side banner from Demonoid. It was as follows ( JavaScript). var O1=document.getElementById('navtower').parentNode;
O1.parentNode.removeChild(O1); This simple snippet is a useful example that is used for a lot of webpage operations. Most web page scripting just involves finding objects and then manipulating them and their parent objects. There are two common ways to get the reference to objects on a web page. One is document.getElementById, and another is through form objects in the DOM. With the first getElementById, you can get any object by passing it’s id tag, for example, <div id=example>
<script language=JavaScript>
var MyObject=document.getElementById('example');
</script>
This function is used so often, many frameworks also abbreviate it with a function: function GE(Name) { return document.getElementById(Name); } I know of at least one framework that actually names the function as just a dollar sign $. The second way is through the name tag on objects, which both the form and any of its form elements require. Only form elements like input, textarea, and select can use this. <body>
<form name=MyForm>
<input type=text name=ExampleText value=Example>
</form>
<script language=JavaScript>
document.MyForm.ExampleText.value='New Example'; //Must use format document.FormName.ObjectName
</script>
</body>
This is the very basis of all JavaScript/web page (client side only) programming. The rest is just learning all the types of objects with their functions and properties. So, anyways, yesterday, Demonoid changed their page so it no longer worked. All that needed to be done was change the ' navtower' to ' smn' because they renamed the object (and made it an IFrame). This kind of information is very easy to find and edit using a very nice and useful FireFox extension called FireBug. I have been using this for a while to develop web pages and do editing (for both designing and JavaScript coding) and highly recommend it. 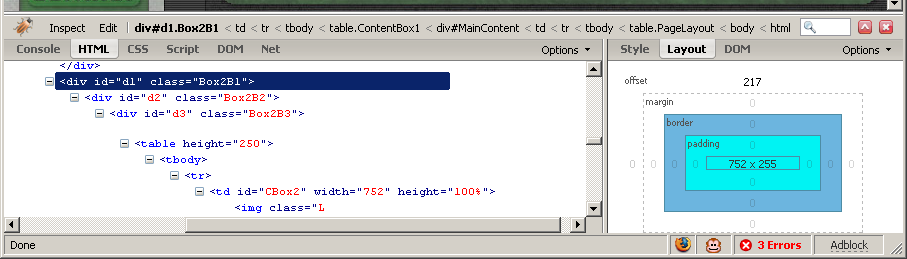
|
|

